Having fun with DALL-E 2
I have beta access to DALL-E 2 and I’ve played around with it this weekend. It’s incredible. However, there’s one “problem”. It requires interesting prompts to produce interesting images.
Any creative project I start eventually suffers from the same issue. I’m not a creative person. I run out of ideas quite fast. It turns out this problem has an easy fix.
Intro
We need to first understand how DALL-E works. More precisely how we use it, not how it actually works. Nobody really knows how machine learning works besides multiplying lots of matrices.
Today there’s no official API for DALL-E 2. You get a prompt bar where you can put the input text and you get out 4 images. You can also input an image and get variations on it. Image sizes are fixed and there’s a report button in case something goes horribly wrong. Easy!
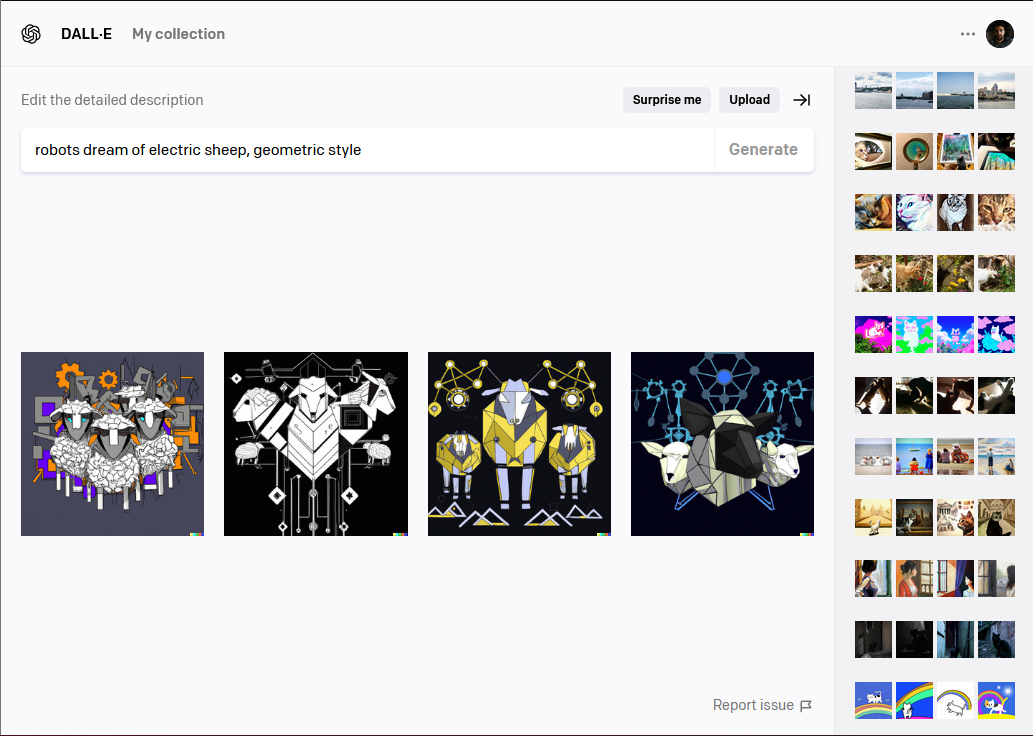
You get some free tokens every month and generating a series of 4 images consumes one token. I’ve spent my initial ones on genrating images of cats doing things and Formula 1 cars. While images with cats are always cool and interesting, I can honestly say that I couldn’t generate interesting images of Formula 1 cars. I wanted to generate one for a friend but it’s just not possible. Please save your tokens and don’t even try. Even “Formula 1 car made from jellybeans” had dissapointing results. We can only hope DALL-E 3 will tackle the problem of interesting looking (by my standards) Formula 1 cars.
The limited free tokens are the least of my problems. You can always buy more, and the prices are relatively reasonable for the amount of fun provided. As I said before, my biggest problem is that I have zero creativity. DALL-E is successful in automating the creation of images from a given text, but this solves half of the problem – that I can’t draw. We need to go further. We also need to have a good title for our image. A good title is 90% of any creative work, just like a good variable name.
Generating titles
This means that we need to automate the generation of image titles (prompts). OpenAI, the creators of DALL-E already have our backs here, as they also have GPT3. This one is pretty good at doing things with text.
How would we go about generating descriptions of interesting images? This is easy, we don’t even need to fine-tune a GPT3 model. We need to inject some examples in the prompts for GPT3. The prompts that I used look like this:
Generate a Title for a painting
Title: A cat reading a book, watercolour painting
Title: A cat drawing a picture of another cat, pencil drawing
Title: vacuum cleaner in a museum
Title: anger as abstract art
Then we make a request to GPT3’s completion API with the prompt above. For the model I’ve used the most beefy one davinci-02.
I set the temperature to 0.9 so it produces more funky stuff.
I get a few responses back (set them to 5), clean them up a bit, keep the interesting ones and put them in the title pool. Over time that title pool increases so everything that follows Title: is chosen as random from the list of previous titles I liked.
Here are some images that DALL-E made from GPT3-generated titles:
the first step, watercolor painting

an old man and his cat, oil painting

A surrealist garden party

Colorful abstract art

a cat made of clouds in a garden party vaporwave

From wiskers to purrs, geometric art

my grandfather’s study

a cat’s life, acrylic painting

Conclusion
I’m like an art curator, these two collaborate and generate things for me, and I just keep the ones I like. I’m sure there are better ways to go about this and further improve the title generation, but I’ve found quite a lot of enjoyment in discovering what they create.
There are some questions people may be interested in and that make up for good Medium articles such as:
Can AIs be creative?
Do humans have any unique traits left that a machine can’t simulate?
Will we all live in pods surviving on disgusting soup?
I don’t know and I don’t care.
In the meantime, I’ll sit back and enjoy watching these “Cats in conversation”:
